The Shortest Guide to Web Scraping in Python

Hi, I'm Isaac, a multifaceted tech professional with expertise in data analysis, content writing, technical writing, video editing, product management, and customer service.
I enjoy using my diverse skillset to create engaging content and provide helpful solutions for readers and clients. Though my background spans many industries, my passion lies in leveraging technology and creativity to clearly communicate complex topics.
When I'm not writing articles or editing videos, you can find me learning new skills, keeping up with the latest tech trends, and looking for new challenges to tackle.
I'm excited to share my knowledge and continue growing as a professional.
Roughly 328.77 million terabytes of data are created daily on the internet. With the advancement of AI, data has become more relevant than ever. One of the common programming languages for collecting and gathering data is Python.
Python provides you with an ecosystem you can turn to when working on a web scraping project. You’ll see how to use Python and its libraries for your web scraping task.
Prerequisites
You’ll need the following knowledge and tools:
Make sure Python is installed on your computer
Basic understanding of Python and pip for installing libraries
Basic understanding of HTML
Getting started with BeautifulSoup
BeautifulSoup is a well-known Python library for parsing XML and HTML documents. It makes it easy to navigate and extract data from web pages.
To get started with BeautifulSoup, install it using pip:
pip install beautifulsoup4
When a webpage is processed, BeautifulSoup constructs a parse tree that is used to extract content from HTML; this makes it an effective tool for parsing web pages.
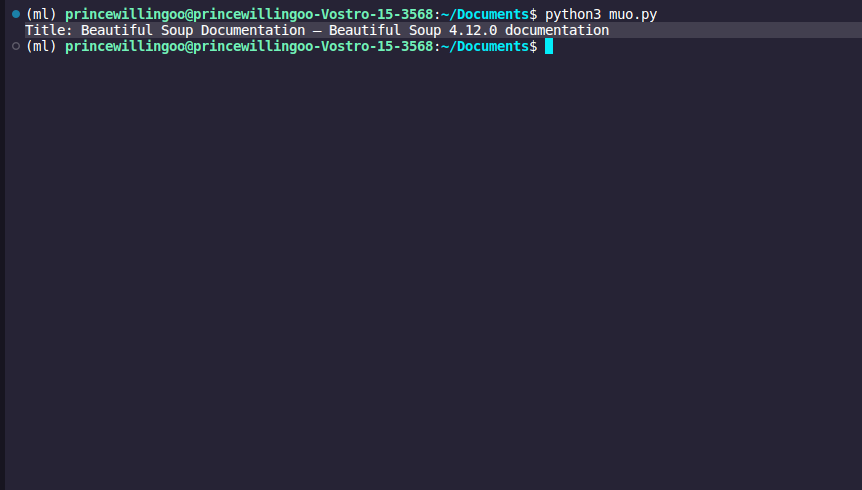
Here’s a basic example of extracting data from a webpage:
from bs4 import BeautifulSoup
import requests
# Send an HTTP request to the URL
response = requests.get('https://www.crummy.com/software/BeautifulSoup/bs4/doc/')
# Create a soup object
soup = BeautifulSoup(response.text, 'html.parser')
# Find and extract data
title = soup.title.text
print(f"Title: {title}")
Using selenium for interactivity
Although BS4 works great with static sites, most websites rely heavily on JavaScript. Selenium allows you to interact with and scrape websites that rely heavily on JavaScript for rendering content.
Run the command below to install Selenium and webdriver-manager packages. The webdriver-manager package helps you set up a Selenium webdriver conveniently on your machine.
pip install selenium webdriver-manager
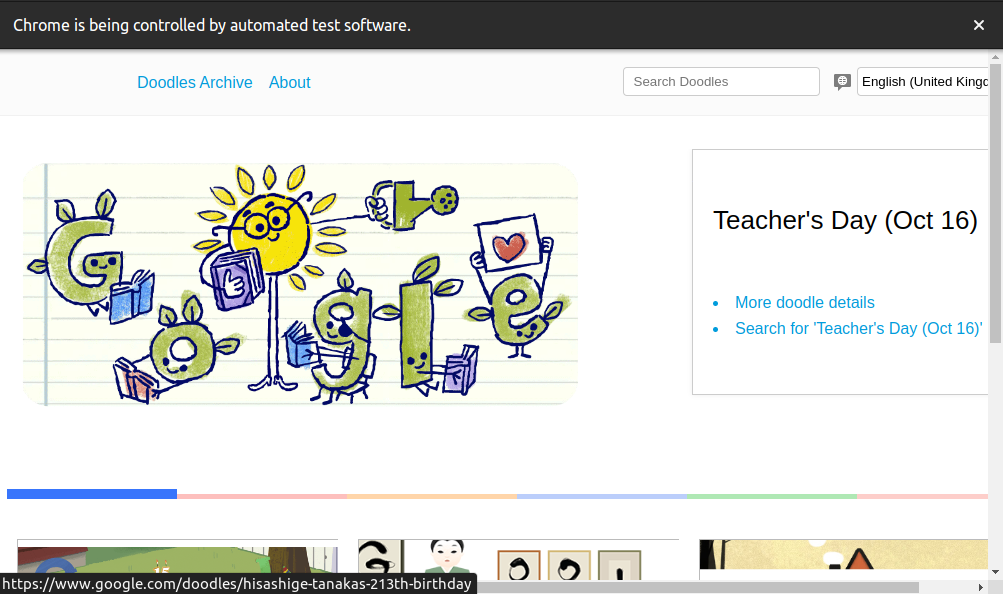
Below’s an example that opens Google's homepage and clicks the "I'm Feeling Lucky" button:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
# create driver instance
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get('https://www.google.com/')
# Find and click the button
feeling_lucky_button = driver.find_elements(By.CLASS_NAME, 'RNmpXc')
feeling_lucky_button[1].click()
WebDriverWait(driver, 15)
Selenium provides you with a plethora of methods and functionality to enable you to interact with websites through your code.
Querying an API directly
Many websites provide APIs (Application Programming Interfaces) that allow you to retrieve structured data directly. This is often the most reliable and ethical way to obtain data from a website.
To query an API directly, use the requests library to make HTTP requests to the API endpoints.
import requests
response = requests.get('https://www.reddit.com/r/python/top.json')
data = response.json()
# process the data
print(data)
Using API libraries
There also exist API libraries created by the community. These libraries simplify the process of interacting with the website's data. For instance, TikTokAPIPy is a Python library for scraping TikTok data.
pip install TikTokAPIPy
Here’s an example use case:
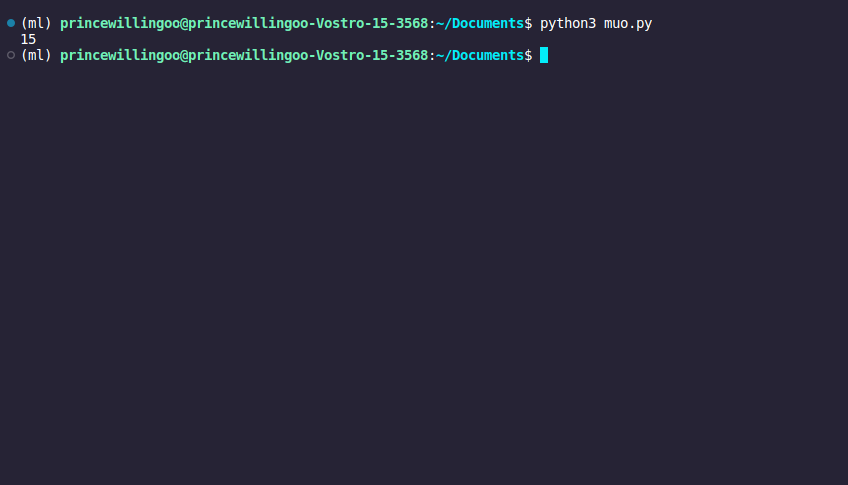
from tiktokapipy.api import TikTokAPI
with TikTokAPI() as api:
user = api.user("daveyhert", video_limit=5)
print(dict(user.stats)["video_count"])
Conclusion
This guide introduced you to four different methods of web scraping in Python. Whether you choose BeautifulSoup for static web pages, Selenium for dynamic content, direct API queries, or specialized API libraries, remember to scrape responsibly and respect a website's terms of use and policies.



